# What is a SQL index?
In most RDBMS's you can use indexes to speed up queries, particularly filters using WHERE and JOINs.
However, in exchange writing new rows to a table will take slightly longer, and the database will take up a bit more disk space.
An index is a table on which searching is efficient due to its specific structure.
You can tell the database to create an index for a given column in a table, such as users.username. Then a new index table is created. Whenever you search based on the users.username table, the database will instead use the index table to search.
# How indexes work (or, an introduction to Balanced Trees)
In order to understand how indexes provide a speed boost to queries, we need to understand why searching the index table is faster than searching the original table.
Index tables are structured like a Balanced-Tree (known as B-Tree). This structure has been especially designed for fast searching. This is what it may look like:
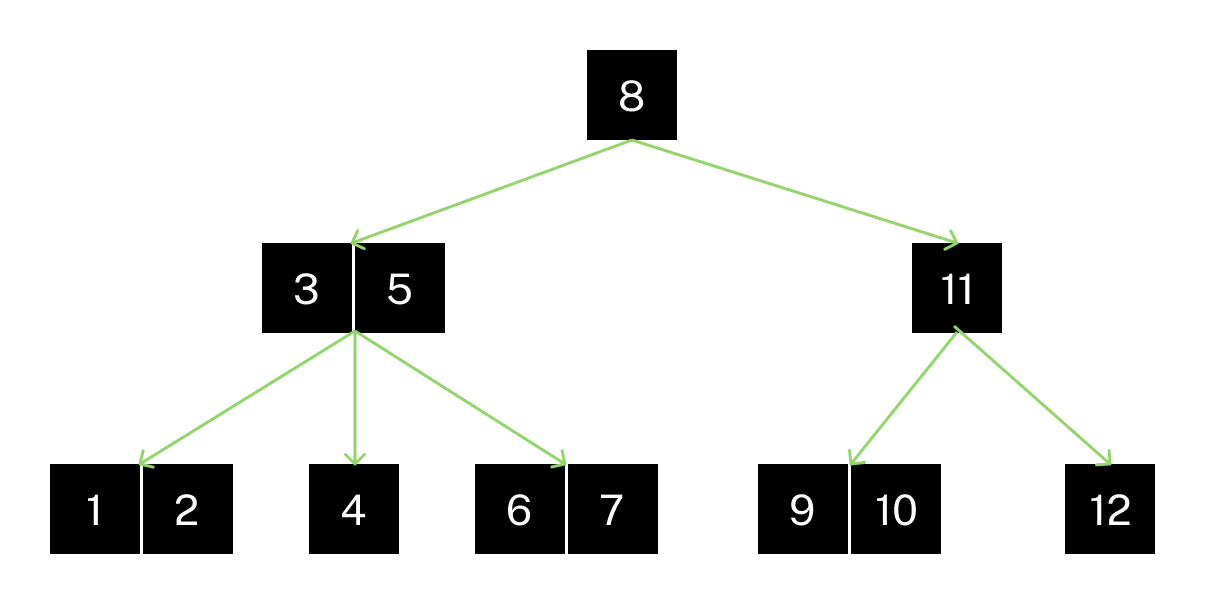
A few important things about this:
- The "root" node is at the top.
- Every node to the left of another node has a smaller value.
- Every node to the right of another node has a bigger value.
For example, the node 9 is at the right of 8, but at the left of 11.
Some nodes can have more than one key, such as 3,5. Because it has 2 keys, it means it will have 3 children: some being smaller than both keys, some being between the two keys, and some being greater than both keys.
This type of structure is fairly tricky to produce programmatically. But fortunately for us, we don't have to. The database will do it for us.
However it's interesting to understand why it is faster to search with this structure than it would be with a flat structure.
Let's say you have the same structure, sorted but flat:

And let's say you were looking for number 9. A reasonable, but slow, strategy would be to start at the beginning, going through each item one by one, and stop when you've found it.
That would take 9 "searches".
However with the B-tree, it would only take 3 "searches", starting at the root.:
- Since 9 > 8, go to the right node,
11. - Since 9 < 11, go to the left node,
9,10. - Find the value in that node.
Earlier I mentioned that producing the B-tree structure programmatically is tricky. Not only is it tricky to code, but can also take some time for the computer to do. That's because an important feature of B-trees is that no branch can be much larger than any other branch. Sometimes when adding nodes to a B-tree, we have to move other nodes around to keep this constraint valid.
The database does that for us, but again it takes a little bit of time.
That is why when you insert data into a table that uses indexes, that insertion can take longer than doing the same on a table that does not use indexes. That's because the index table has to be kept up to date with the new data inserted.
Finally, because using indexes means creating a separate index table with the B-tree structure, more disk space is required when using indexes.
# Wrapping Up
Indexes will speed up your "reads": retrieving and searching for data in a database.
But they will slow down your "writes": inserting data.
In addition, more disk space will be required for your index tables.
Therefore it makes most sense adding indexes to tables that will be used much more often for reading than for writing.